

Cognitive AI is The Next Scientific Frontier in Machine Intelligence
From Explainability
to Cognition
The first generation of modern AI, statistical AI, focused on optimizing performance through scale: more parameters, more data, deeper networks. The second generation, explainable AI (XAI), sought to interpret model outputs, using saliency maps, feature attributions, and slice discovery to reveal how models behave. While valuable, these approaches remain diagnostic. They help humans analyze errors after the fact, but do not change how models make decisions.
Cognitive AI represents a third generation. It embeds reasoning within the system itself, enabling models to:
Map
the geometry of success and failure in training data.
DETECT
when an input falls into regions of ambiguity or uncertainty.
TRIGGER
adaptive interventions when predictions are unreliable.
Rather than functioning as a black box with a static confidence threshold, Cognitive AI actively monitors its own decision-making and adjusts dynamically. It operationalizes explainability into an ongoing cognitive process.
From Explainability
to Cognition
The first generation of modern AI, statistical AI, focused on optimizing performance through scale: more parameters, more data, deeper networks. The second generation, explainable AI (XAI), sought to interpret model outputs, using saliency maps, feature attributions, and slice discovery to reveal how models behave. While valuable, these approaches remain diagnostic. They help humans analyze errors after the fact, but do not change how models make decisions.
Cognitive AI represents a third generation. It embeds reasoning within the system itself, enabling models to:
Map
the geometry of success and failure in training data.
DETECT
when an input falls into regions of ambiguity or uncertainty.
TRIGGER
adaptive interventions when predictions are unreliable.
Rather than functioning as a black box with a static confidence threshold, Cognitive AI actively monitors its own decision-making and adjusts dynamically. It operationalizes explainability into an ongoing cognitive process.
As artificial intelligence systems have grown more complex, so too has the demand to explain their decisions.
In response, feature attribution techniques such as saliency maps, SHAP values, LIME, and attention visualizations, have become standard tools for “opening up” black-box models. These methods promise to show which inputs mattered most, which features influenced an outcome, and why a model arrived at a particular decision.
And yet, despite widespread adoption, feature attribution has failed to deliver what organizations actually need: a reliable understanding of how models behave, why they fail, and when they should not be trusted.
This failure is not accidental. It is not the result of immature tooling or insufficient visualization. It is the consequence of a deeper mismatch between what feature attribution measures and how modern AI systems actually reason.
What Feature Attribution Is Designed to Do
Feature attribution methods
answer a narrow question:
Which input features contributed most to this output?
They operate by:
- Perturbing inputs and measuring output sensitivity
- Approximating local linear behavior around a prediction
- Tracing gradients or attention weights backward through the network
In controlled settings, these techniques can be informative. They may highlight pixels that influenced an image classification or words that shaped a text prediction. They are useful for debugging data pipelines, detecting obvious leakage, or satisfying surface-level transparency requirements.
But they were never designed to explain behavior. And that distinction matters.
The Core Problem: Models Do Not Reason in Feature Space
Modern deep learning systems do not operate on features in isolation. They transform inputs into latent representations: high-dimensional, nonlinear, and entangled internal states that encode meaning geometrically rather than symbolically.
By the time a prediction is made:
- Individual input features have been mixed
- Interactions dominate isolated effects
- Semantic meaning is distributed across the latent space
Feature attribution attempts to map behavior back onto inputs as if decisions were still made in feature space. But they are not.This is the fundamental flaw.
Why Feature Attribution Fails (Structurally)
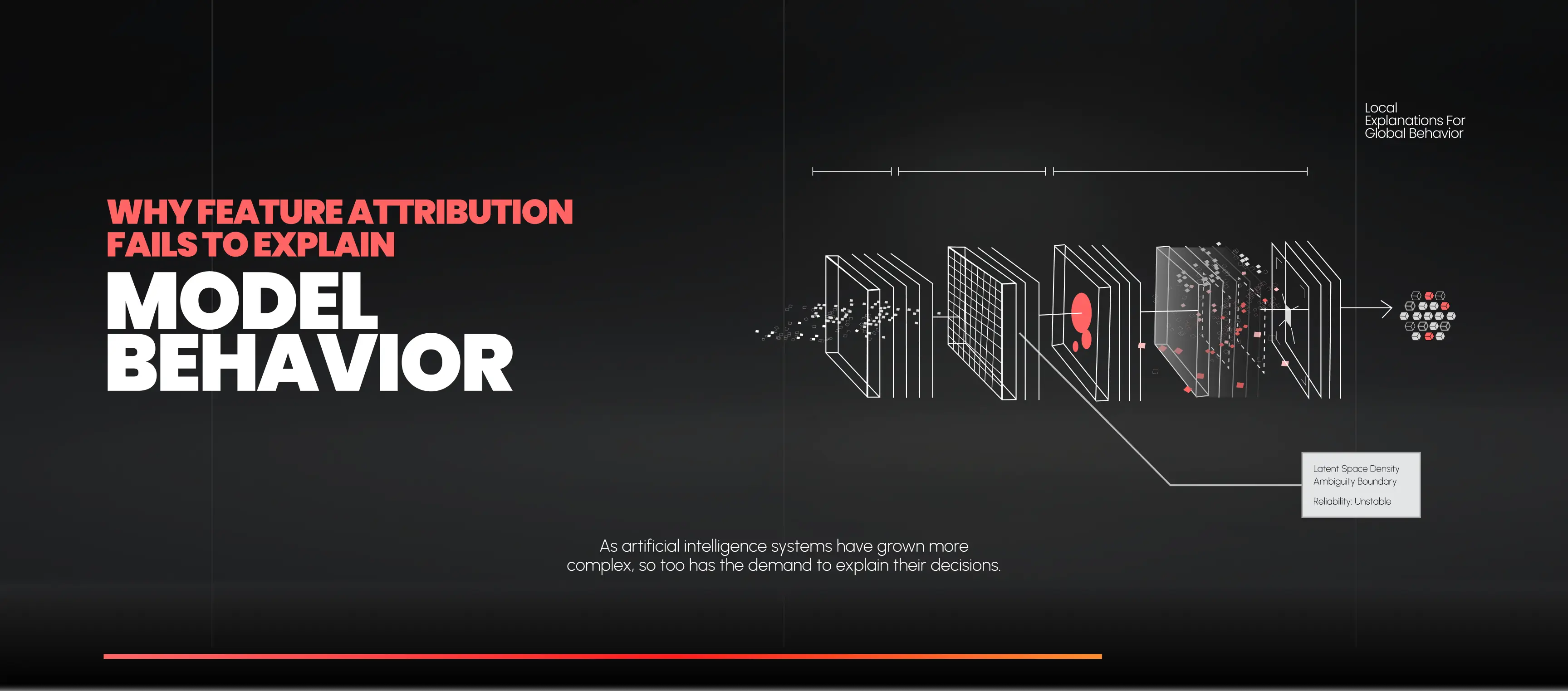
1. Local Explanations for Global Behavior
Most attribution methods are local. They explain why a model produced this output for this input, assuming the surrounding decision surface is stable.
In reality, many AI failures are global phenomena:
- Entire regions of latent space where the model is unreliable
- Clusters where shortcut learning dominates
- Boundaries where ambiguity causes instability
A local explanation cannot reveal these structures. It may look plausible while the system as a whole is operating in a fragile regime.
2. Attribution Explains Sensitivity, Not Reliability
Feature attribution measures sensitivity: how much changing an input affects the output. But sensitivity is not the same as trustworthiness.A model can be highly sensitive to the “right” features and still be wrong. It can focus on semantically meaningful regions and still operate in a part of latent space where training support is sparse or failure is common.
Attribution may tell you what the model looked at. It cannot tell you whether the model should be trusted.
3. Attribution Is Blind to Latent Geometry
The most important signals of failure live in latent space:
- Distance from reliable regions
- Proximity to error clusters
- Novelty relative to prior experience
- Density of training support
- Overlap between competing classes
Feature attribution never measures these.
It has no notion of:
- Where the representation sits in the model’s internal geometry,
- Whether similar representations have failed historically,
- Whether the model is extrapolating beyond its knowledge.
As a result, attribution can appear reassuring even as the system drifts into dangerous territory.
4. Attribution Cannot Detect Shortcut Learning Reliably
One of the most damaging failure modes in AI is shortcut learning: when models rely on spurious correlations rather than true causal features.Feature attribution often confirms shortcuts rather than exposing them.
Why?
Because shortcuts are genuinely predictive in the training distribution. The model is not “cheating” from its own perspective, it is optimizing the loss function it was given.
Attribution may faithfully show that the model relied on a hospital marker, scanner artifact, or background pattern.
But it cannot tell you:
- Whether this reliance is structurally fragile
- Whether it will fail under distribution shift
- Whether this shortcut defines a dangerous region of latent space
5. Attribution Is Retrospective, Not Preventive
Perhaps most critically, feature attribution is post-hoc. It explains decisions after they are made.
In high-stakes systems: medical diagnostics, autonomous vehicles, and financial trading. this is insufficient. What matters is not why a failure occurred, but whether it could have been anticipated and prevented. Feature attribution offers insight after the fact. It provides no mechanism to intervene before an error becomes real.
Why This Makes Debugging AI So Hard
When AI systems fail, engineers are left with:
- A wrong output
- Little understanding of the underlying cause
- A plausible attribution map
Because attribution does not reveal latent structure:
- Failures are difficult to reproduce
- Fixes introduce new regressions elsewhere
- Root causes remain ambiguous
The system appears to “work” until it doesn’t and attribution provides no early warning.This is why organizations often experience repeated failures despite extensive explainability tooling.
What Explanation Actually Requires
To explain model behavior, not just individual predictions, an AI system must expose:
- Where a decision lies in latent space
- How dense or sparse that region is
- Whether similar representations have failed before
- How close the system is to ambiguity or novelty boundaries
- How internal geometry is shifting over time
These are not feature-level properties. They are representational properties.
How SQUINT Cognition Goes Beyond Attribution
SQUINT Cognition is built on the recognition that explanation must operate at the level where decisions are actually made.
Instead of attributing outputs to inputs, SQUINT:
- Maps the internal representation space of models
- Identifies regions of reliability, ambiguity and failure
- Learns the geometric signatures of shortcut learning and drift
- Deploys runtime watchdogs that monitor these signals continuously
When a model’s internal state moves into a risky region, SQUINT intervenes before the decision is executed: escalating, deferring, or altering behavior. This transforms explanation from a descriptive exercise into a control mechanism.
From “Why Did This Happen?” to “Should This Happen?”
Feature attribution answers the question:
Why did the model produce this output?
Cognitive AI answers a more important one:
Should the model be allowed to act on this output?