

Cognitive AI is The Next Scientific Frontier in Machine Intelligence
Modern artificial intelligence systems have achieved remarkable performance across vision, language, and decision-making tasks. They classify medical images with near-expert accuracy, navigate complex roadways, and generate fluent language at scale.
And yet, despite these advances, AI systems remain fundamentally fragile. They fail in unexpected ways, produce confident errors, and resist meaningful debugging when things go wrong.
At the heart of this fragility lies a less
discussed but deeply structural problem:
AI systems cannot see, understand, or reason about their own internal representations.
This lack of transparency is not a usability issue or a tooling gap. It is a direct consequence of how modern machine learning models are designed. To understand why AI remains opaque and why that opacity leads to unreliability, we must examine how meaning is encoded inside neural networks.
Where AI Decisions
Actually Happen
When an AI model processes an input, it does not reason symbolically or logically. Instead, it transforms raw data into a latent representation: a high-dimensional vector that encodes how the model perceives the input.
In a vision system, this might be a 512- or 1024-dimensional vector representing shapes, textures, lighting, and context. In a language model, it may represent semantic relationships across tokens. In all cases, the final prediction is derived from this internal state.
Crucially, This latent space is where decisions are made.
And yet, this space is almost never examined.
Why Latent Spaces Are
Inherently Hard to Interpret
Latent representations possess three defining characteristics:
High dimensionality
Information is spread across hundreds or thousands of dimensions. No single dimension corresponds to a human concept.
Nonlinearity
Small changes in input can cause large, unintuitive shifts in representation.
Entanglement
Features are encoded in distributed patterns. A single neuron or activation has no stable semantic meaning.
Because of this, inspecting individual neurons or dimensions tells us almost nothing. Meaning does not live in parts, it lives in geometry.
What Geometry Reveals
About Model Behavior
Although latent spaces are difficult to interpret directly, their structure is highly informative:
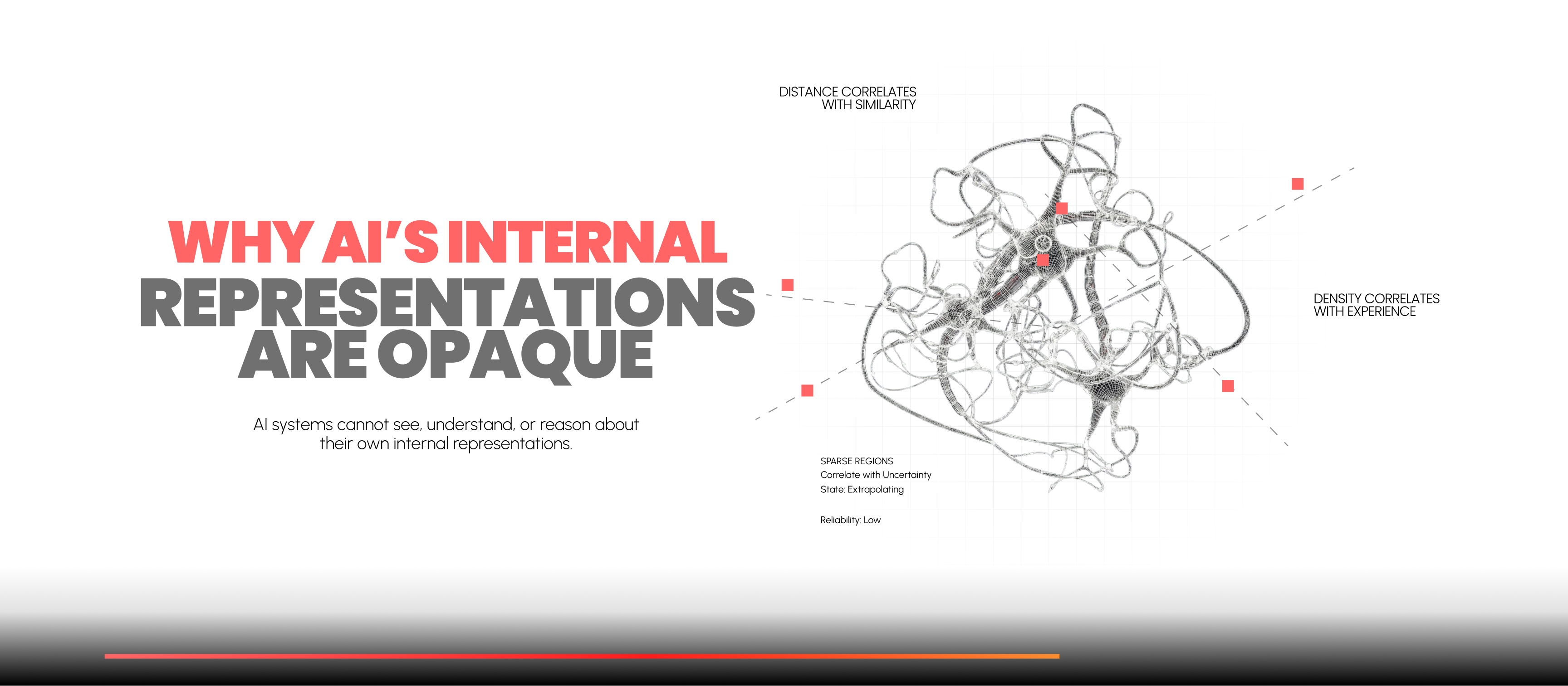
Distance correlates with similarity
Inputs the model considers similar are mapped close together.
Density correlates with experience
Dense regions correspond to patterns the model has seen frequently during training.
Clusters correlate with behavior
Reliable predictions, systematic errors, shortcut-driven decisions, and biases all form distinct clusters.
Sparse regions correlate with uncertainty
Inputs in low-density areas are cases where the model is extrapolating.
In other words, model failures are not random. They occur in specific, repeatable regions of the latent space.
What Traditional AI
Systems Ignore
Despite the importance of this geometry, conventional AI pipelines do not:
- Measure distance to reliable regions
- Track density or support
- Identify error-prone clusters
- Monitor movement through latent space over time
- Expose this information to developers or operators
Instead, the latent representation is immediately passed to a decision head, and then discarded. What remains is a label and a confidence score, numbers that say nothing about why the model believes its answer is trustworthy.
This is why AI systems fail silently.
Why Debugging AI Becomes Nearly Impossible
When an AI system makes a mistake, engineers can observe: the input, the incorrect output, and perhaps a confidence score.
What they cannot see is the internal state that produced the error.
Because latent representations are: not logged, not visualized, and not compared against know faliure regions.
engineers are left guessing. Reproducing the failure often requires recreating the exact same latent conditions, which may depend on noise, timing, sensor quality, or subtle context shifts.
This leads to AI failures that feel: non-deterministic, non-local, and resistant to traditional debugging.
The Consequence: AI
Without Self-Awareness
Human decision-making includes a
continuous assessment of reliability:
“This seems unfamiliar.”
“I might be wrong here.”
“I should slow down.”
AI systems lack this capacity entirely.
They do not know:
- When they are extrapolating
- When their internal representation is unstable
- When they are relying on shortcuts
- When ambiguity dominates the input
As a result, they act with misplaced certainty, especially in the edge cases that matter most.
How SQUINT Cognition
Solves the Problem
SQUINT Cognition introduces a fundamentally different approach. Instead of treating latent representations as an internal detail, SQUINT Cognition treats them as the primary signal for reliability.
During development, SQUINT Cognition analyzes a model’s intermediate representations to:
- Map clusters of correct decisions
- Identify regions associated with historical failures
- Isolate ambiguity boundaries
- Characterize zones of novelty
This creates a reliability map of the model’s internal reasoning space.
At runtime, SQUINT Cognition deploys lightweight cognitive watchdogs that continuously monitor where new inputs land within this map. When a representation approaches a known error region or drifts into unfamiliar territory, SQUINT Cognition intervenes before the model commits to a decision.
That intervention may take many forms:
- Escalating to a more robust model
- Deferring to human judgment
- Altering system behavior to reduce risk
- Suppressing automation entirely
The key is that correction occurs before failure, not after.
From Opaque Models to
Thinking Systems
By making latent geometry visible and actionable, SQUINT Cognition transforms AI systems from opaque predictors into context-aware decision makers.
The system no longer asks only “What is the answer?”
But also “How trustworthy is this answer, given what I know and what I’ve seen before?”
This shift from output-centric inference to representation-centric reasoning is what enables AI to self-regulate, adapt, and evolve over time.
Transparency as a
Prerequisite for Trust
AI will not become trustworthy by growing larger or more accurate alone. Trust emerges when systems understand their own limitations, anticipate failure, and adjust behavior accordingly.
The opacity of latent representations is the root cause of AI’s fragility.
Making that internal geometry visible is the path forward.
SQUINT Cognition exists to do exactly that: