

Table of Content
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Table of Content
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
COCO Dataset Overview
Please note that Squint Vision Studio defines a “Datasource” as a collection of data used to train and evaluate a model (e.g. CoCo) and a “Dataset” as a datasource descriptor created in Squint Vision Studio to manage the datasource.
Subset of COCO Dataset Classification (10 Classes)
This guide walks you through a complete workflow in Squint Vision Studio using a custom 10-class subset of the COCO datasource. You will learn how to set up a project, creating a COCO dataset from the COCO datasource importing a model, and leveraging Squint Vision Studio's tools to thoroughly evaluate, interpret, and monitor your model's performance.
The following sections will walk you through how to use Squint Vision Studio, so it is expected that you have the Studio open and have obtained a valid license.
1.
Project Setup: COCO
1. Project Setup
Creating a Project
- Navigate to the Project tab.
- Click Load to open an existing project or click the + icon next to Manage
Projects to create a new one. - Name your project (e.g., COCO 10-Class Classification) and optionally add a description.
- Click Save.
2. Dataset: CIFAR-10
2.
Dataset: COCO Subset (10 Classes)
Preparing the datasource
The COCO datasource should be placed in the SquintVolume/DataSources directory and structured as follows:
- A top-level folder should be created with the datasource name (e.g. COCO_subset).
- Inside, create two subfolders: train and test.
- Each of these contains 10 subfolders, one for each class:
- Airplane
- Bicycle
- Boat
- Bus
- Car
- Dog
- Horse
- motorcycle
- person
- train
Each class folder should contain the corresponding image files.
To build a custom subset of the COCO dataset with 10 classes that aligns with the Squint data structure, follow these steps:
1. Download the Dataset from the official COCO dataset website.
After extraction, your directory should look like this:
COCO_official/
├── train2017/
├── val2017/
└── annotations/
├── instances_train2017.json
└── instances_val2017.json2. Each image in COCO may contain multiple objects. To simplify classification, we:
- Identify the object with the largest bounding box in each image.
- Keep only images where this dominant object belongs to one of the targeted 10 classes.
This ensures that each image is labeled with a single, dominant class.
3. Save in Squint-Compatible Folder Structure
Filtered images are saved in a directory structure compatible with Squint:
COCO_subset/
├── train/
│ ├── airplane/
│ ├── bicycle/
│ └── ...
└── test/
├── airplane/
├── bicycle/
└── ...- Images from train2017 go into the train/ folder.
- Images from val2017 go into the test/ folder.
- Each class has its own subfolder.
This structure is ideal for training and evaluating classification models using Squint or similar tools.
Example code to create a COCO datasource
The COCO dataset is typically provided in a JSON-based annotation format along with a large collection of image files. Each image is accompanied by detailed annotations including object labels, bounding boxes, segmentation masks, and other metadata. This format is ideal for training models that require rich contextual information, such as object detection or image captioning. However, it does not match the folder-based structure required by Squint Insights Studio. Squint Insights Studio expects the dataset to be organized into directories by class label, with each image saved as an individual file within its respective class folder. Therefore, we need to convert the dataset from its annotation-driven format into a structured directory format, where images are grouped by their primary object class, using the code below.
Copied!

import os
import shutil
from collections import defaultdict
from pycocotools.coco import COCO
from tqdm import tqdm
# Path to COCO dataset annotations and images
coco_root = 'COCO_official'
image_dirs = {
'train': os.path.join(coco_root, 'train2017'),
'val': os.path.join(coco_root, 'val2017')
}
ann_dir = os.path.join(coco_root, 'annotations')
output_base_dir = 'SquintVolume/DataSources/COCO_subset'
# Categories to include
target_categories = [
'airplane', 'bicycle', 'boat', 'bus', 'car',
'dog', 'horse', 'motorcycle', 'person', 'train'
]
# Function to process a split
def process_split(split_name, output_subdir):
dataType = f'{split_name}2017'
annFile = os.path.join(ann_dir, f'instances_{dataType}.json')
coco = COCO(annFile)
output_dir = os.path.join(output_base_dir, output_subdir)
os.makedirs(output_dir, exist_ok=True)
image_class_mapping = defaultdict(str)
for img_id in tqdm(coco.imgs, desc=f"Processing {split_name} images"):
img_info = coco.loadImgs(img_id)[0]
img_file = os.path.join(image_dirs[split_name], img_info['file_name'])
ann_ids = coco.getAnnIds(imgIds=img_id)
anns = coco.loadAnns(ann_ids)
if anns:
largest_ann = max(anns, key=lambda x: (x['bbox'][2] * x['bbox'][3]))
cat_id = largest_ann['category_id']
cat_info = coco.loadCats(cat_id)[0]
class_name = cat_info['name']
if class_name in target_categories and img_info['id'] not in image_class_mapping:
image_class_mapping[img_info['id']] = class_name
class_dir = os.path.join(output_dir, class_name)
os.makedirs(class_dir, exist_ok=True)
shutil.copy(img_file, os.path.join(class_dir, img_info['file_name']))
print(f"Total {split_name} images saved: {len(image_class_mapping)}")
# Process both splits
process_split('train', 'train')
process_split('val', 'test')
print("COCO subset has been saved with 'train' and 'test' folder structure.")Creating the Dataset
- In the Studio, navigate to Data ⇀ Load.
- Click the + icon to Create a new dataset.
- Select the COCO data source.
- Apply data preprocessing as illustrated in the image below.
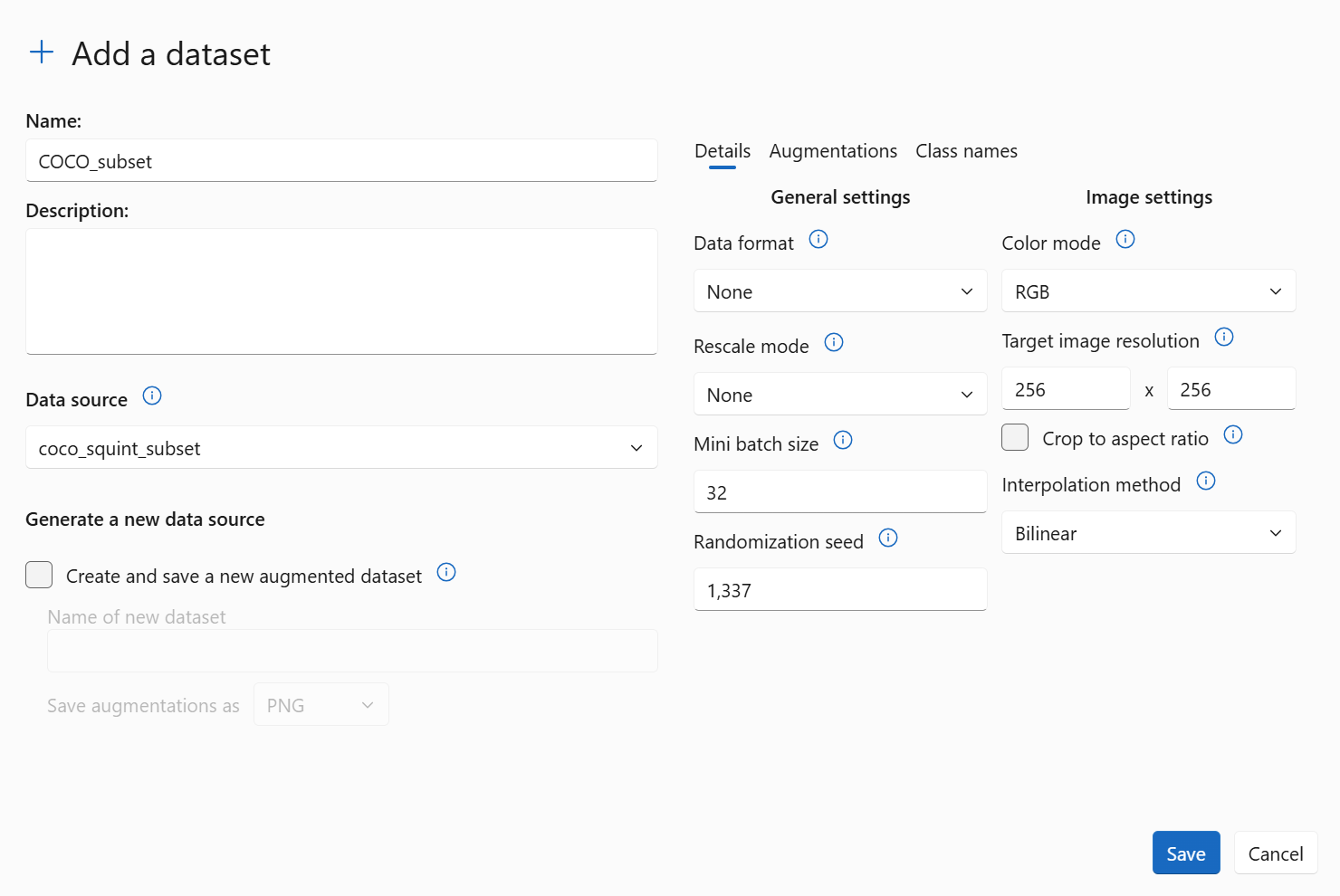
We use a target image resolution of 256×256 pixels to match the expected input size of our model (which we will define below). The original COCO datasource contains images of varying resolutions and aspect ratios, so resizing them to a fixed size ensures consistency across the dataset and compatibility with convolutional neural networks. Since COCO images are in RGB format, each image has three channels, which aligns with the input format expected by most deep learning models. Therefore, we chose the color mode as RGB.
We also set the mini batch size to 32, which is a commonly used value that balances computational efficiency and memory usage during training. This setup ensures that the model receives consistent input dimensions and well-scaled data throughout the training process.
We also set the mini batch size to 32, which is a commonly used value that balances computational efficiency and memory usage during training. This setup ensures that the model receives consistent input dimensions and well-scaled data throughout the training process.
- Save the dataset.
Exploring the COCO Subset
Navigate to Data ⇀ Load the dataset ⇀ View – Browse COCO Images Using the Image Carousel
The View feature provides an interactive image carousel that lets you visually inspect the images in the COCO subset.
- Scroll through images by category to verify data quality and labeling.
- Confirm that images are correctly grouped by class.
- Identify any anomalies, such as misclassified or low-quality images.
This tool is especially useful for validating the dataset before training or evaluating models.
Navigate to Data ⇀ Load the dataset ⇀ Metrics – View per-class sample distribution and dataset statistics
The Metrics feature offers a statistical overview of the COCO subset.
- View the number of samples per class in both training and test sets.
- Detect any class imbalances that could affect model performance and bias.
- Review the overall dataset size and class diversity.
These insights are essential for diagnosing potential biases and ensuring the dataset is well-prepared for training and evaluation.
Navigate to Data ⇀ Load the dataset ⇀ Histogram – Analyze per-class pixel intensity distributions
The Histogram feature visualizes the pixel intensity distributions for each class.
- Analyze brightness and contrast patterns across different categories.
- Detect inconsistencies or anomalies in image quality.
- Compare visual characteristics between classes to assess uniformity.
This tool helps ensure that the dataset is visually consistent and suitable for model training.
3. Model: CIFAR-10 Classifier
3.
Model: COCO Classifier
Uploading the trained Model
- Navigate to the Model ⇀ Load page.
- Load a previously added model, or click on the + icon to add a vision model trained on COCO to the studio.
Note: The model must be trained before uploading. Squint Vision Studio is not intended for training models; it is designed for deploying and analyzing already-trained models. Ensure your model is trained externally and then uploaded to the studio.
Below is an example of how you can build and train a model using a YOLOv8 small backbone pre-trained on the COCO datasource, before uploading it to Squint Vision Studio:
Structure of the CNN Model
Copied!
import keras_cv
import tensorflow as tf
import numpy as np
# model setup
backbone = keras_cv.models.YOLOV8Backbone.from_preset(
"yolo_v8_s_backbone_coco", # We will use yolov8 small backbone with coco weights
input_shape=(256,256,3),
)
backbone.trainable = False
model = tf.keras.layers.GlobalAveragePooling2D()(backbone.output) #GAP method
model = tf.keras.layers.Dense(10, activation='softmax')(model) #GAP method
model = tf.keras.Model(inputs=backbone.input, outputs=model)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())Training the CNN Model
Copied!
# data setup
data_path = '/SquintVolume/Datasets/COCO_subset/train'
dataset = tf.keras.utils.image_dataset_from_directory(directory=data_path,
labels='inferred', label_mode='categorical', batch_size=32, image_size=(256, 256),
shuffle=True, seed=1337, validation_split=None) #Categorical
batch_count = len(dataset)
classes = [c for c in dataset.class_names]
print("Dataset info")
print("========================================")
print("\n")
print(f"Batch count: {batch_count}")
print(f"Classes: {classes}")
# Training loop
loss_batch = 0
epoch_metric = tf.keras.metrics.CategoricalAccuracy() #Categorical
#epoch_metric = tf.keras.metrics.SparseCategoricalAccuracy() #Sparse
for epoch in range(3):
print(f"Epoch: {epoch}")
#for batch in range(60):
for batch in range(batch_count):
batch_metric = tf.keras.metrics.CategoricalAccuracy() #Categorical
#batch_metric = tf.keras.metrics.SparseCategoricalAccuracy() #Sparse
images, labels = dataset.as_numpy_iterator().next()
with tf.GradientTape() as tape:
predictions = model(images, training=True)
loss = tf.keras.losses.categorical_crossentropy(labels, predictions) #Categorical
#loss = tf.keras.losses.sparse_categorical_crossentropy(labels, predictions) #Sparse
gradients = tape.gradient(loss, model.trainable_weights)
model.optimizer.apply_gradients(zip(gradients, model.trainable_weights))
epoch_metric.update_state(labels, predictions)
batch_metric.update_state(labels, predictions)
if batch % 100 == 0:
print(f"Batch: {batch}, Loss: {loss}")
print(f"Batch: {batch}, Accuracy: {batch_metric.result().numpy()}")
print("\n\n")
print(f"Epoch: {epoch}, Accuracy: {epoch_metric.result().numpy()}")
epoch_metric = tf.keras.metrics.CategoricalAccuracy() #Categorical
#epoch_metric = tf.keras.metrics.SparseCategoricalAccuracy() #Sparse
model.save("squint_yolov8_classifier_v2_balanced_gap.keras")
#model.save("squint_yolov8_classifier_v2_sparse.keras")Explore the model and capture intermediate representations
- Use the View feature to inspect the model graph.
- Click on model nodes to view layer details.
- Select a node and click Generate Model to create a squinting model that captures intermediate outputs. A squinting model is a modified version of your original model designed to capture and output intermediate activations from specific layers during inference. This step is crucial as we will need to evaluate how your model sees the data (e.g. by capturing the embeddings of a layer deep in the model) before we can proceed to create a discovery.
- Once you click “Generate Model” from a model node, navigate back to the Model ⇀ Loadpage and load the newly created squinting (“SQ”) model.
In this project, we applied a"global_average_pooling2d"layer to the output of the backbone network. The output of this pooling layer, with a shape of (None, 512), serves as our feature extraction layer, as illustrated in the model structure shown below. This means we are capturing the 512-dimensional feature vector produced for each input sample at this stage, allowing us to analyze how the model represents data after the backbone has processed it.
.webp)
4. Discovery: Evaluating the CIFAR-10 Model
4.
Discovery: Evaluating the COCO Model
Creating a Discovery
- Navigate to the Discovery ⇀ Load page.
- Click on the + icon to create a new discovery.
- The model will run inference on the COCO dataset and generate performance metrics.
Discovery ⇀ Metrics
- Analyze mistake distributions across classes for both training and testing sets. The image below illustrates how errors are distributed per class, helping to identify which categories are more prone to misclassification.
.webp)
- Evaluate overall model performance on training and testing sets. Identify the best and worst performing classes.
- Examine per-class performance metrics, including accuracy, F1 scores, and error distributions for both training and testing sets.
- Inspect confusion matrices for training and testing sets to identify commonly misclassified categories.
- View dataset information used in this discovery, including details of the COCO subset and any augmentations applied during preprocessing or training.
Discovery ⇀ Analyze
- Explore the embedding space of the model (based on the layer selected when creating the squinting model) using the Cognitive Atlas. Int he Cognitive Atlas you can explore the relationships your model sees in the data by analyzing scatter plots for both training and testing data (select “train”or “test” sunder Image Source). You can analyze the model’s perception for all classes at once, or by selecting specific classes using the “class filter”control; by default, all classes are shown.
Below is a cognitive atlas generated for this project, illustrating the embedding space on the COCO training data:
.webp)
- Analyze the embedding space by selecting different Display options to view all data points, correct predictions, false positives, and false negatives. You can also filter by class using the selection bar on the right (default shows all classes).
The image below shows false positive errors across all classes in the COCO training data, visualized on the scatter plot.
.webp)
As shown in the image, most errors are concentrated near the edges of the clusters in the embedding space. These boundary areas, which we refer to asambiguous regions, represent zones where the model struggles to distinguish between classes. In these regions, the feature representations of different classes overlap or are very close, making it difficult for the model to make confident predictions. As a result, predictions in ambiguous regions are less reliable and more prone to error.
In contrast, the central areas of the clusters referred to as trusted regions; are where the data points are more densely packed and clearly separated from other classes. These regions reflect high-confidence zones where the model consistently makes correct predictions. The lack of errors in these areas suggests that the model has learned strong, discriminative features for those examples, making its predictions more dependable.
Understanding the distribution of errors in the embedding space helps in diagnosing model behavior, identifying areas of uncertainty, and guiding improvements such as targeted data augmentation or model calibration.
In contrast, the central areas of the clusters referred to as trusted regions; are where the data points are more densely packed and clearly separated from other classes. These regions reflect high-confidence zones where the model consistently makes correct predictions. The lack of errors in these areas suggests that the model has learned strong, discriminative features for those examples, making its predictions more dependable.
Understanding the distribution of errors in the embedding space helps in diagnosing model behavior, identifying areas of uncertainty, and guiding improvements such as targeted data augmentation or model calibration.
- Use the DensityMap option in Squint Vision Studio to visualize the distribution of data in the embedding space.
When All Data is selected in the Display menu, the Density Map shows the overall data distribution. The image below shows the Density Map for the data on the COCO subset training set. As you can see in the image, the densest regions are located at the center of the clusters, while the edges represent areas of lower density.
.webp)
When False Positive or False Negative is selected in the Display menu, it highlights areas with the highest concentration of mistakes. This helps identify problematic regions or cells in the embedding space. By focusing on these areas; such as setting triggers or targeted improvements; you can enhance model performance more effectively. The image below shows the Density Map for Incorrect Predictions on the COCO subset training set:
.webp)
- Interactively explore ambiguous regions in the embedding space by clicking on cells located near the edges of clusters in the scatter plot. These edge cells often represent areas where the model is uncertain, leading to a higher likelihood of misclassifications. When you click on a cell, you can view detailed cell statistics and browse the image gallery of similar embeddings within that region.
The image below showscell statisticsfor a selected cell in an ambiguous region of the COCO training data:
.webp)
Cell Statistics
These represent the full statistics for the cell, regardless of filters:
- Total Data Count: 399
- Cell Accuracy: 39%
- Correct Prediction Count: 155
- Error Count: 244
Correct Prediction Distribution
This breakdown shows how many correct predictions were made per class within the cell:
- Class Horse: 1
- Class Motorcycle: 74
- Class Person: 80
Error Distribution
This breakdown shows the number of misclassifications per class:
- Class Motorcycle Errors: 3
- Class Person Errors: 241
This cell highlights substantial misclassification between the 'person' and 'motorcycle' classes, indicating they are the most frequently confused.
The image below shows image gallery for a selected cell in an ambiguous region of the COCO training set:
.webp)
As you can see, the images are ambiguous and not clearly recognizable.
You can also select the Input Saliency option (top-right corner of the image gallery) to highlight which parts of the images influenced the model's predictions, as shown below:
You can also select the Input Saliency option (top-right corner of the image gallery) to highlight which parts of the images influenced the model's predictions, as shown below:
.webp)
- Interactively explore trusted regions in the embedding space by clicking on cells located near the center of clusters, typically represent areas where the model is trustworthy, resulting in fewer misclassifications. Clicking on a cell reveals cell statistics and an image gallery of consistent embeddings.
The image below shows cell statistics for a selected cell in trusted region of the class person of the COCO training set:
.webp)
Cell Statistics:
- Total Data Count: 162
- Cell Accuracy: 100%
- Correct Prediction Count: 162
- Error Count: 0
Correct Prediction Distribution:
- Class cat: 162
The image below shows the image gallery for a selected cell in the trusted region of the class person of the COCO training set:
.webp)
As you can see, the images are clear and consistent, making them easier to recognize.
You can also select the Input Saliency option (top-right corner of the image gallery) to highlight which parts of the images influenced the model's predictions, as shown below:
You can also select the Input Saliency option (top-right corner of the image gallery) to highlight which parts of the images influenced the model's predictions, as shown below:
.webp)
5. Trigger: Monitoring CIFAR-10 Predictions
5.
Trigger: Monitoring COCO Predictions
A trigger is a set of conditions that a user can design using the Cognitive Atlas to monitor the predictions of a model at runtime.
Note: that a premium license is required to access the Trigger feature.
Note: that a premium license is required to access the Trigger feature.
Creating a Trigger
- Go to Discovery → Analyze.
- Click the + button in front of Trigger conditions to create a new trigger.
- Select cells in the embedding space where the model shows uncertainty or frequent misclassifications.
- These selected cells will appear in the create Triggers dialog.
- Define the trigger condition (e.g., "If the input falls in cell (9, 7), fire alert misclassification between person and motorcycle").
- Save the trigger.
Exporting a Trigger
- Navigate to the Trigger → Export page.
- View the trigger's conditions as diagrams showing:
- The monitored cells for each prediction.
- The alert value returned when the condition is met.
- Exporting a trigger generates a runtime watchdog.
- The watchdog can be integrated into your application using the Squint watchdog API to monitor predictions and flag ambiguous or out of distribution inputs in real time.
Example: Creating a Trigger for Class Person Mistakes
Let's walk through an example of how to identify an ambiguous region for class person, which contains the highest number of samples.
Step 1: Analyze Training Mistakes
- Navigate to the Discovery → Analyze page.
- Under “Image source” select “Train” and under “Display” select “False positives”.
- Hover over different cells in the embedding space for the class person.
- Identify the cell with the lowest accuracy. In this case, cell (9, 7) shows an accuracy of 39%, indicating it's a region where the model frequently misclassifies inputs.
- We consider cell (9, 7) an ambiguous region for the class person.
Step 2: Validate with Testing Mistakes
- Switch to Test data and False positives mistakes and locate cell (9, 7) in the cognitive atlas.
- Confirm that this cell also has the lowest accuracy for the class person in the test set which is 57%.
- This consistency across training and testing data reinforces that cell (9, 7) is a reliable indicator of uncertainty.
Step 3: Define a Trigger
- Based on this insight, define a trigger condition:
If the model predicts class person and the input falls within cell (9, 7), then send a signal indicating the prediction is not trustworthy.
This trigger helps your application flag uncertain predictions in real time, improving reliability and interpretability of the model's decisions.
This trigger helps your application flag uncertain predictions in real time, improving reliability and interpretability of the model's decisions.
6. Benefits of Using Squint Insights Studio
6.
Advantages of Squint Vision Studio
Understand Model Behavior Through Semantic Analysis
Squint Vision Studio enables deep semantic exploration of your model's embedding space. By visualizing how data points cluster and where errors occur, you can gain a clearer understanding of how your model perceives and organizes information. This insight is crucial for:
- Identifying ambiguous regions where the model is uncertain.
- Differentiating between types of mistakes based on their location in the cognitive atlas.
- Recognizing patterns in misclassifications that may not be obvious from raw metrics alone.
Improve Model Performance Based on Purpose
The platform allows you to tailor your model improvement strategy to your specific use case by leveraging the spatial structure of the embedding space.
For example:
- You can set custom triggers to monitor specific types of errors.
Example: If misclassification between person and motorcycle is particularly important, you can define a rule like: "If the model predicts person and the input falls in cell (9, 7), fire alert: Misclassification between person and motorcycle." - Once this trigger is activated, you can route the flagged sample to a secondary model; one that is specifically trained to distinguish between person and motorcycle. This secondary model, being more specialized, is likely to be more reliable in resolving that specific confusion.
This approach allows you to layer your models intelligently, using the general model for broad classification and specialized models for high-risk or high-importance distinctions.
- This layered approach allows you to:
- Prioritize and address high-impact errors.
- Reduce false positives or negatives in sensitive areas.
- Improve overall system reliability without over complicating the primary model.
Model Adjustment Without Retraining
Retraining a model can be time-consuming, expensive, or even infeasible in production environments. Squint Vision Studio offers a powerful alternative: adjusting model behavior without retraining.
For example:
For example:
- In the COCO dataset, the person class has the highest number of samples and includes a wide variety of poses; such as standing, sitting, lying down, or crouching.
- These variations can lead to ambiguity in the embedding space, especially when different poses cluster separately.
- Instead of retraining the model to better distinguish these pose variations, you can split the person class into sub-classes based on their location in the scatter plot. This allows you to treat different poses as distinct behavioral patterns.
- By doing so, you extend the model's output space and adapt to nuanced requirements without modifying the model weights; enabling more precise control and improved performance.
Flexible, Interactive, and Cost-Efficient
Squint Vision Studio empowers you to:
- Interactively explore and annotate the embedding space.
- Set up real-time alerts for specific error patterns.
- Make structural changes to your model's interpretation of data without retraining.
- Save time and resources while maintaining high model performance and adaptability.
7. Insights: Summarizing the CIFAR-10 Project
7.
Insights: Summarizing the COCO Project
The Insights section serves as a critical component in understanding and communicating the outcomes of the COCO project. It consolidates key findings, performance metrics, and model behavior into a structured, shareable format. This not only aids in internal analysis but also enhances transparency and collaboration with stakeholders.
Creating an Insight Report
To generate a comprehensive Insight report:
- Navigate to Insights → Load.
- Click the + icon to create a new Insight report.
The generated report includes:
- Dataset Details
Information such as class distribution for both training and testing sets. - Model Metrics and Performance
Information such as the model's size, training parameters, and evaluation metrics (e.g., accuracy, precision, recall) provides a snapshot of its effectiveness. - Discovery Results
Visual tools like confusion matrices and saliency maps reveal how the model interprets data and where it may struggle, offering opportunities for refinement. - Trigger Definitions and Monitored Conditions
These highlight specific conditions or thresholds that were set to monitor model behavior, ensuring robustness and reliability in deployment. - Recommendations
The recommendations feature in the Studio's Insight report is designed to provide automated, data-driven guidance for improving the performance and quality of your machine learning project. It analyzes key metrics from your dataset and model evaluation, then generates targeted suggestions to help you optimize results.
Exporting an Insight
To share or archive the report:
- Go to Insights → Export.
- Export the Insight report as a detailed summary of the COCO project.
This exported report is invaluable for:
- Documentation:
Keeping a record of model development and evaluation. - Presentations:
Communicating results to technical and non-technical audiences. - Stakeholder Engagement:
Providing clear, data-driven insights to support decision-making. - Recommendations Tracking
Reviewing automated suggestions for improving dataset balance, per-class performance, and overall model quality. These recommendations help guide iterative improvements and ensure the project evolves toward higher accuracy, fairness, and robustness.
Why It Matters:
The Insight report transforms raw data and model metrics into actionable knowledge. It bridges the gap between development and deployment, ensuring that everyone - from engineers to executives - can understand and trust the outcomes of the COCO project.
Summary
This sample project demonstrates how to use Squint Vision Studio to evaluate a model trained on the 10-class COCO datasource. By following these steps, you can gain deep insights into your model's behavior, identify ambiguous regions, and improve reliability through real-time monitoring.
In summary, Squint Vision Studio is more than just a visualization tool; it's a semantic control center for your model, enabling smarter diagnostics, targeted improvements, and flexible adaptation to evolving needs.
In summary, Squint Vision Studio is more than just a visualization tool; it's a semantic control center for your model, enabling smarter diagnostics, targeted improvements, and flexible adaptation to evolving needs.